日文编码系统与乱码关系解析之探究
在当今数字化的时代,我们经常会遇到各种编码系统,而日文编码系统有着其独特性。当它与其他因素相互作用时,可能会引发乱码现象,这给信息的准确传递和处理带来了一定挑战。
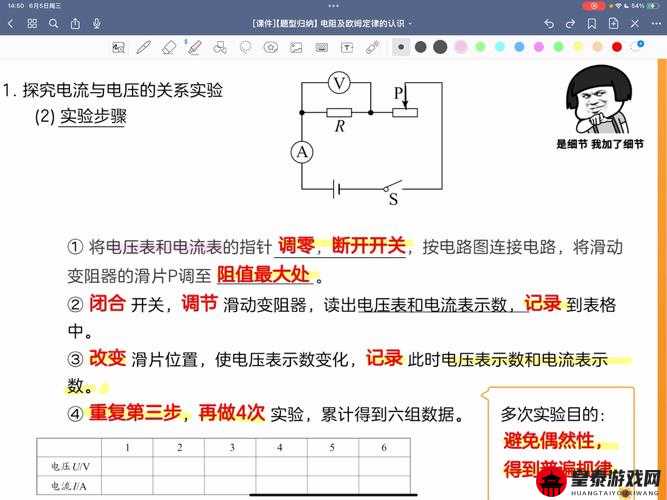
日文编码种类
日文编码主要有 Shift_JIS、EUC-JP 等几种常见类型。Shift_JIS 编码在早期被广泛应用,它对日文字符有较好的表示能力。EUC-JP 则具有更高的兼容性和准确性。这些不同的编码方式在处理日文文本时有着各自的特点和适用场景。
不同的编码系统在存储和传输日文信息时,可能会因为转换不当而导致乱码的出现。比如在不同的操作系统或软件之间进行数据交换时,如果编码设置不一致,就容易产生乱码问题。
乱码产生原因
乱码的产生原因是多方面的。除了编码系统的差异外,还可能与文件格式、传输协议等有关。比如,某些文件格式对编码的支持有限,在处理特定编码的日文文本时就容易出错。而传输协议如果不能正确识别和处理编码信息,也会导致乱码在传输过程中产生。
人为操作失误也可能引发乱码。比如错误地设置了编码选项,或者在编辑日文文本时使用了不恰当的工具或方法。
解决乱码方法
针对乱码问题,可以采取多种解决方法。首先要确保系统和软件的编码设置正确,使其与日文文本的编码相匹配。可以通过查看相关设置选项或使用特定的工具来进行调整。
在进行数据交换时,要明确双方所使用的编码方式,并进行适当的转换。对于已经出现乱码的情况,可以尝试使用一些专门的乱码修复工具或软件来进行恢复。
在开发软件或系统时,也要充分考虑到日文编码和乱码问题,做好相应的兼容性和处理机制。
深入了解日文编码系统与乱码的关系对于准确处理日文信息至关重要。通过对编码种类、乱码产生原因和解决方法的全面探讨,我们能够更好地应对在数字化环境中遇到的日文相关问题。未来,随着技术的不断发展,相信会有更加高效和智能的解决方案出现,进一步提升对日文编码和乱码的处理能力。
相关资讯
-

-

抖音上很火的一群人玩的追人游戏叫什么?超好玩的多人追逐游戏下载
抖音上很火的一群人玩的追人游戏,是一款超好玩的多人追逐游戏。游戏规则简单易懂,玩家需要在规定的时间内完成任务,同时避免被追逐者抓住... -

-

-

敢问猫在何方第 7 关怎么过?资深博主教你 7 步通关图文攻略
在游戏的世界里,每一个关卡都像是一座等待攀登的山峰,充满了挑战与未知。而敢问猫在何方的第 7 关,更是让不少玩家陷入了困境。别担心... -
-

-
